Excel如何抓取网页数据之JSON数据抓取
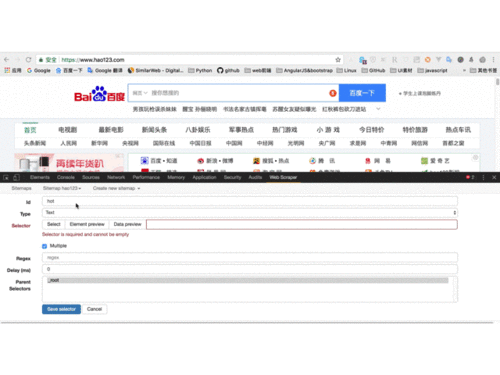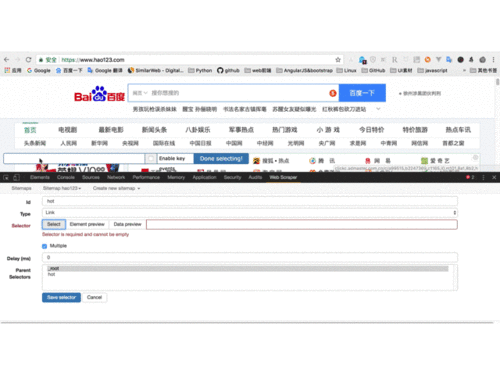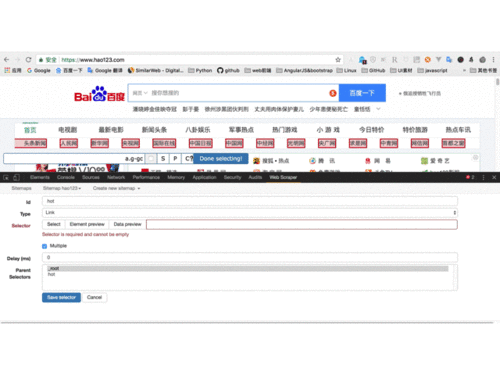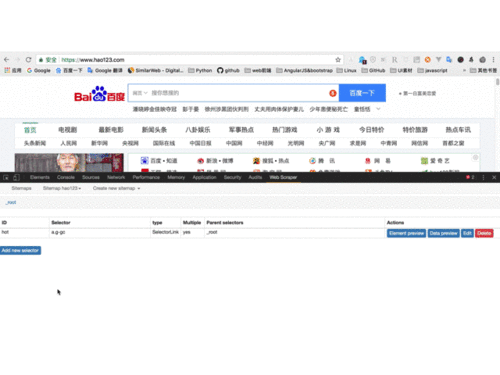
打开Chrome,在拉勾网搜索深圳市的“数据分析”职位,使用检查功能查看网页源代码,发现拉勾网有反爬虫机制,职位信息并不在源代码里,而是保存在JSON的文件里,因此我们直接下载JSON,并使用字典方法直接读取数据。
抓取网页时,需要加上头部信息,才能获取所需的数据。
在搜索结果的第一页,我们可以从JSON里读取总职位数,按照每页15个职位,获得要爬取的页数。再使用循环按页爬取,将职位信息汇总,输出为CSV格式。
程序运行如图:
抓取结果如图:
数据清洗占数据分析工作量的大头。在拉勾网搜索深圳市的“数据分析”职位,结果得到369个职位。查看职位名称时,发现有4个实习岗位。由于我们研究的是全职岗位,所以先将实习岗位剔除。由于工作经验和工资都是字符串形式的区间,我们先用正则表达式提取数值,输出列表形式。工作经验取均值,工资取区间的四分位数值,比较接近现实。
4. 词云
我们将职位福利这一列的数据汇总,生成一个字符串,按照词频生成词云实现python可视化。以下是原图和词云的对比图,可见五险一金在职位福利里出现的频率最高,平台、福利、发展空间、弹性工作次之。
5. 描述统计
可知,数据分析师的均值在14.6K,中位数在12.5K,算是较有前途的职业。数据分析散布在各个行业,但在高级层面上涉及到数据挖掘和机器学习,在IT业有长足的发展。
我们再来看工资的分布,这对于求职来讲是重要的参考:
工资在10-15K的职位最多,在15-20K的职位其次。个人愚见,10-15K的职位以建模为主,20K以上的职位以数据挖掘、大数据架构为主。
我们再来看职位在各区的分布:
数据分析职位有62.9%在南山区,有25.8%在福田区,剩下少数分布在龙岗区、罗湖区、宝安区、龙华新区。我们以小窥大,可知南山区和福田区是深圳市科技业的中心。
我们希望获得工资与工作经验、学历的关系,由于学历分三类,需设置3个虚拟变量:大专、本科、硕士。多元回归结果如下:
在0.05的显著性水平下,F值为82.53,说明回归关系是显著的。t检验和对应的P值都小于0.05表明,工作经验和3种学历在统计上都是显著的。另外,R-squared的值为0.41,说明工作经验和学历仅仅解释了工资变异性的41%。这点不难理解,即使职位都叫数据分析师,实际的工作内容差异比较大,有的只是用Excel做基本分析,有的用Python、R做数据挖掘。另外,各个公司的规模和它愿意开出的工资也不尽相同。而工作内容的差异和公司的大方程度是很难单凭招聘网页上的宣传而获得实际数据,导致了模型的拟合优度不是很好这一现实。
网页数据抓取如何从网页中抓取数据?
抓取网页是个庞大的工程。但是总结来说,途径只有三个:
1.最原始的方式,手工复制。
2.写代码,很多程序员喜欢这么做,但是要采集个简单的网页容易,要想什么网站都能采集那绝非易事。
3.估计除非是有特殊的喜好,否则大家都不想选择以上两条路,都想要更高效,更强大,最好是免费的一个采集器,目前最好用的采集器是新出的八爪鱼采集器,确实是神器,好像没有搞不定的网站。还免费,值得一试。
什么是网页数据抓取?
就是获取网页的一些数据啊,有的是获取网页内容方面的一些信息,有的是获取你的一些浏览信息。活动信息,点击信息等等。
网页数据抓取需要用到什么技术呢?
爬虫获取。
如何抓取网站上的实时数据
1.找到网址
2.打开网页,查看源码
推荐用Notepad
不了解的去看:
Notepad 的默认HTML查看器
3.找到源码中你所需要的外汇行情的数据
自己找,也只有你自己知道你要啥
4.分析其中的规则,比如对应的是在哪个div等等之内的
5.写正则表达式去提取对应的数据
如果不会写,可以参考前面已经提到的:
【教程】抓取网并提取网页中所需要的信息 之 Python版
对于复杂的内容的提取,不熟悉的话,可以贴出部分来,我再教你如何写正则去提取。
对于更加复杂的,则建议换用Pytho中的BeautifulSoup








